One of the biggest strategic mistakes companies make is measuring AI visibility in a single model.
That’s equivalent to measuring SEO performance only on one search engine.
LLMs differ structurally in:
- Training emphasis
- Knowledge graph reliance
- Reinforcement calibration
- Narrative coherence weighting
True AI competitive intelligence requires cross-model analysis.
1. Why Models Produce Different Winners
Each model weights signals differently.
| Model | Authority Bias Pattern |
|---|---|
| ChatGPT | Context repetition & structure |
| Gemini | Entity & knowledge graph strength |
| Claude | Narrative coherence |
| Perplexity | Citation-based transparency |
A brand strong in contextual reinforcement but weak in structured entity signals may dominate ChatGPT but underperform in Gemini.
2. Cross-Model Benchmark Framework
Visibility Matrix
| Prompt | ChatGPT | Gemini | Claude | Perplexity |
|---|---|---|---|---|
| Best AI visibility platform | 1st | 2nd | 1st | 3rd |
| Enterprise AI positioning tool | 2nd | Not listed | 1st | 2nd |
| AI competitive monitoring software | Not listed | 1st | 2nd | 3rd |
Volatility reveals authority fragmentation.
Example: Cross-LLM Brand Dominance in High-Intent Prompts
In cross-LLM environments, brand authority is not defined by a single model — but by consistency across models.
The example below illustrates how Mercedes-Benz USA performs across 10 high-intent buyer prompts analyzed within the 42A platform, measuring visibility across ChatGPT and Gemini.
Rather than tracking page rankings, the platform evaluates:
- Prompt Coverage
- Total Mentions
- First Position Rate
- Top 3 Presence
- Average Relative Position
This provides a probabilistic inclusion map across leading LLM ecosystems.
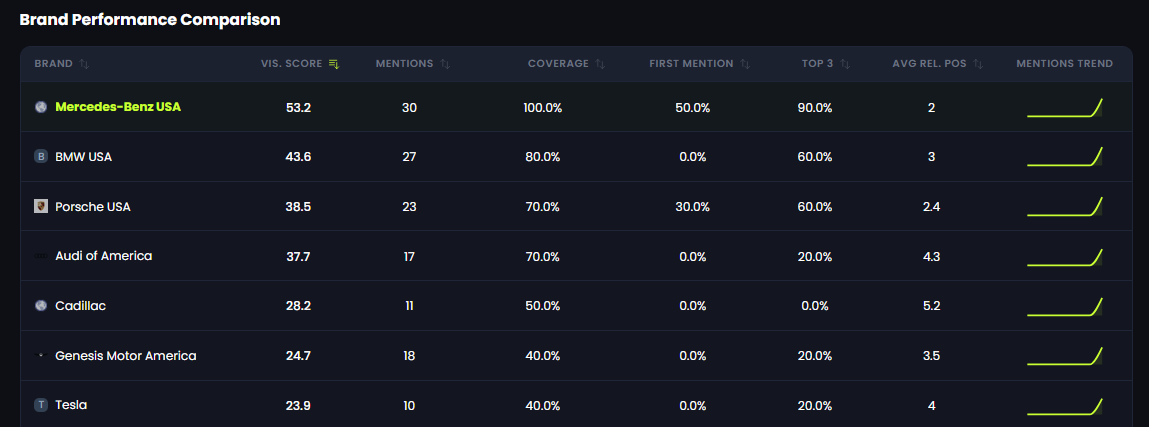
Mercedes-Benz USA achieves 100% high-intent prompt coverage and 90% Top-3 presence across ChatGPT and Gemini — demonstrating stable cross-LLM authority.
Data generated within the 42A AI Visibility Platform.
3. Stability as Authority Signal
In SEO, stable rankings signal authority.
In AI ecosystems, stable inclusion across models signals structural embedding.
Stability Framework
| Inclusion Consistency | Interpretation |
|---|---|
| 80%+ across models | Dominant entity |
| 60–79% | Competitive presence |
| 40–59% | Fragmented authority |
| <40% | Weak embedding |
Stability equals trust.
4. Descriptor Drift
Cross-model analysis must also monitor framing drift.
A brand may be described as:
- “Leading” in one model
- “Emerging” in another
That inconsistency weakens authority perception.
5. Competitive Gap Discovery
Cross-LLM benchmarking exposes more than surface-level ranking differences. It reveals structural authority gaps that are often invisible when analyzing a single model.
A proper gap discovery framework should identify:
- Prompt Gaps – High-intent prompts where competitors appear but your brand does not
- Position Divergence – Scenarios where you rank first in one model but third or lower in another
- Descriptor Drift – Differences in how models frame your brand (e.g., “leading” vs. “emerging”)
- Replacement Asymmetry – A single competitor consistently displacing you across buyer-stage prompts
For example, if your brand dominates ChatGPT results but disappears entirely in Gemini, this likely indicates weaker entity embedding within knowledge graph–weighted environments. If Claude consistently attaches enterprise-level authority descriptors to a competitor while your brand receives neutral framing, that signals contextual reinforcement imbalance.
To operationalize this process, organizations implement structured monitoring systems such as AI Competitive Intelligence, which enable measurable tracking of displacement frequency, descriptor inconsistency, and cross-model dominance gaps.
Instead of reacting anecdotally to isolated AI responses, teams can move toward systematic authority stabilization.
That is the difference between observing AI behavior and controlling visibility strategy.
6. Human Reality
Enterprise buyers use multiple AI systems.
If authority is fragmented, perception becomes fragmented.
Consistency builds category ownership.
Strategic Conclusion
Cross-LLM competitive analysis is not optional.
It is the next evolution of share-of-voice modeling.
Brands that:
- Benchmark inclusion across models
- Monitor position variance
- Track descriptor drift
- Reduce displacement asymmetry
Will stabilize authority in a fragmented AI ecosystem.
AI visibility leadership requires cross-model resilience.
Written by
Eyal Fadlon
Growth marketing specialist